„Der digitale Patient“ will sich in einer Debattenreihe den Möglichkeiten und Grenzen von Big Data im Gesundheitswesen konstruktiv nähern. Unser Blog fungiert dabei als Plattform, wir lassen hier Experten aus verschiedenen Bereichen zu Wort kommen. Prof. Jonas Schreyögg plädierte im vorigen Beitrag dafür, bereits existierende Daten des Gesundheitssystems besser für Forschung und Patienteninformation zu nutzen. Dr. Sarah Fischer schreibt in diesem Beitrag über mögliche Wege, wie wir zu mehr Datensouveränität im Umgang mit Big Data kommen könnten. Die von ihr vorgestellten Konzepte und Ideen basieren auf einer Analyse, die das Center for Democracy and Technology für die Taskforce Digitalisierung der Bertelsmann Stiftung angefertigt hat.
Seit persönliche Daten massenhaft gesammelt und ausgewertet werden, wird es für den Einzelnen zunehmend schwieriger, die Verfügungsmacht über sie zu behalten. Datenschutzkonzepte, die allein auf individuelle Kontrolle setzen, sind den Herausforderungen durch Big Data nicht gewachsen. Es braucht neue Ansätze, die die Datensouveränität der Nutzer in den Mittelpunkt stellen. Sie müssen den Einzelnen befähigen, seine Rechte auch ausüben zu können, ohne ihn mit der alleinigen Verantwortung zu überfordern.

Big Data birgt zweifellos Chancen, Krankheiten besser zu erkennen oder Gesundheitsangebote zu personalisieren. Doch Big-Data-Anwendungen stellen neue Anforderungen an den Schutz von Patienten- und anderen personenbezogenen Daten. Denn Big Data hebelt Prinzipien bisheriger Datenschutzregime aus: Dem Transparenzgrundsatz steht die Komplexität der Auswertungen entgegen. Der Datensparsamkeit widerspricht das Ziel, eine möglichst große Datenbasis zu generieren. Das Prinzip der Zweckbindung wird umgangen, wenn Auswertungsziele erst nach der Datenerhebung festgelegt werden.
Vor diesem Hintergrund verwundert es nicht, dass Internetnutzer resigniert sind und sich machtlos fühlen, wenn es um die Sicherheit ihrer persönlichen Daten geht. Dieser Kontrollverlust führt zu Misstrauen – und das behindert das Potenzial von Big Data in der Medizin wie auch in anderen Bereichen.
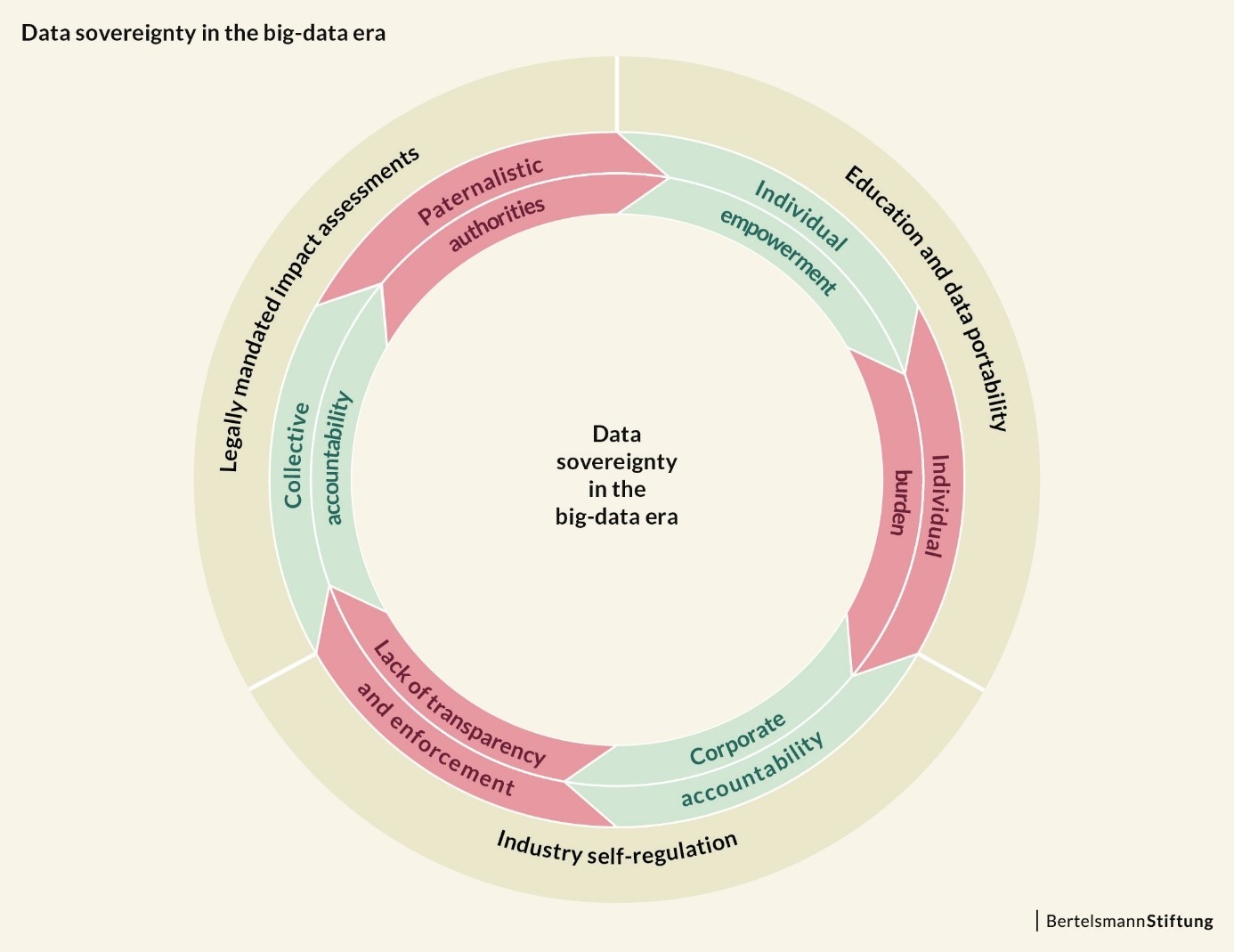
Wie können Bürger also auch in Zeiten von Big Data Herr über ihre Daten bleiben? Wir brauchen eine zeitgemäße Interpretation von individueller Kontrolle. Die Befähigung des Einzelnen sowie unternehmerische und staatliche Verantwortung sollten sich dabei bestmöglich ergänzen – rund um das Konzept von Datensouveränität.
Nutzer-Empowerment durch Bildung
Mit dem Fokus auf Datensouveränität rückt der aktive Nutzer in den Mittelpunkt. Damit er tatsächlich souverän mit seinen Daten umgehen kann, braucht es mehr als entsprechende rechtliche Rahmenbedingungen. Es sind vor allem zielgruppenspezifische Bildungsangebote notwendig. Auch digitale Technologien selbst können zur Befähigung beitragen, etwa in Form von Erklärungstools für Datenschutzbestimmungen („Digitaler Daten-Beipackzettel“) oder durch Apps, über die man nachverfolgen kann, wo man wem welche persönlichen Daten zur Verfügung gestellt hat.
Datensouveränität darf jedoch Datenschutz nicht vollständig ersetzen. Denn der Einzelne kann und sollte nicht die gesamte Last der Verantwortung tragen – gerade im Hinblick auf die Machtasymmetrie zu den großen Datensammlern. Damit Datensouveränität und Datenschutz sich gegenseitig ergänzen können, sind auch kollektive Ansätze nötig.
Unternehmerische Verantwortung durch Selbstregulierung
Unternehmen können mit freiwilligen Selbst-Evaluationen mehr Klarheit für Nutzer schaffen, wie ihre Daten verwendet werden und welche Konsequenzen dies für sie hat. Das kann zu mehr Vertrauen und einem Differenzierungsmerkmal im Wettbewerb führen. Erste Unternehmen wie der Schweizer Telekommunikationsanbieter Swisscom haben das bereits erkannt. Ansätzen der Selbstregulierung mangelt es jedoch oft an Durchsetzungskraft.
Staatliche Verantwortung durch Risikoabschätzung unabhängiger Dritter
Aus diesem Grund sind ergänzend auch obligatorische staatlich beauftragte Risikoprüfungen durch unabhängige Dritte notwendig – ähnlich wie etwa in der Pharma- oder Automobilindustrie, wo mögliche Risiken und ihre Bedeutung für die Kunden bereits in der Produktentwicklungsphase analysiert werden. Sie können die Konsequenzen der Verarbeitung und Nutzung großer Datenmengen analysieren, ethische Aspekte beleuchten und die Ergebnisse öffentlich machen. Zudem muss staatliche Regulierung für verlässliche Rahmenbedingungen und einen Ausgleich von Machtungleichheiten sorgen. Hier schließt sich der Kreis: Denn damit solche Maßnahmen nicht in paternalistischer Bevormundung enden, braucht es wiederum Nutzer-Empowerment. Der Einzelne muss seine Rechte (und Pflichten) verstehen und in der Lage sein, diese für sich zu nutzen.
So greifen die drei vorgeschlagenen Ansätze ineinander und gleichen ihre jeweiligen Schwachstellen aus. Angesichts der vielfältigen Herausforderungen durch Big Data ist solch ein multiperspektivisches Konzept ein vielversprechender Ansatz für Datensouveränität im digitalen Zeitalter.
Abonnieren Sie jetzt unseren Newsletter, um über neue Blog-Beiträge per E-Mail informiert zu werden.
Alle Artikel der Debattenreihe Big Data anzeigen